Comparing Cross Entropy and KL Divergence Loss
Entropy is the number of bits required to transmit a randomly selected event from a probability distribution. A skewed distribution has a low entropy, whereas a distribution where events have equal probability has a larger entropy. A skewed probability distribution has less “surprise” and in turn a low entropy because likely events dominate. Balanced distribution are more surprising and turn have higher entropy because events are equally likely.
Entropy H(x) can be calculated for a random variable with a set of x in X discrete states discrete states and their probability P(x) as follows:
$$ H(x) = -\sum_x p(x)log(p(x))$$Cross-entropy builds upon the idea of entropy from information theory and calculates the number of bits required to represent or transmit an average event from one distribution compared to another distribution.
Cross-entropy can be calculated using the probabilities of the events from P and Q, as follows:
$$ H(P,Q) = -\sum_x p(x)log(q(x))$$KL divergence measures a very similar quantity to cross-entropy. It measures the average number of extra bits required to represent a message with Q instead of P, not the total number of bits. K L divergence can be calculated as the negative sum of probability of each event in P multiples by the log of the probability of the event in Q over the probability of the event in P. Typically, log base-2 so that the result is measured in bits.
$$KL(P||Q) = -\sum_x p(x)log(q(x)/p(x))$$We compare the impact of KL and Cross Entropy Loss on the Convnets
# KL Divergence Loss
import tensorflow as tf
import tensorflow.keras as keras
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten
from tensorflow.keras.layers import Conv2D, MaxPooling2D
batch_size = 250
no_epochs = 25
no_classes = 10
(input_train, target_train), (input_test, target_test) = cifar10.load_data()
input_train = input_train.astype('float32')
input_test = input_test.astype('float32')
input_train = input_train / 255
input_test = input_test / 255
target_train = keras.utils.to_categorical(target_train, no_classes)
target_test = keras.utils.to_categorical(target_test, no_classes)
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(32,32,3)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dense(no_classes, activation='softmax'))
model.compile(loss=keras.losses.kullback_leibler_divergence,
optimizer=keras.optimizers.Adam(),
metrics=['accuracy'])
history=model.fit(input_train, target_train,
batch_size=batch_size,
epochs=no_epochs,
validation_split=0.2
)# Cross Entropy Loss
import tensorflow as tf
import tensorflow.keras as keras
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten
from tensorflow.keras.layers import Conv2D, MaxPooling2D
batch_size = 250
no_epochs = 25
no_classes = 10
(input_train, target_train), (input_test, target_test) = cifar10.load_data()
input_train = input_train.astype('float32')
input_test = input_test.astype('float32')
input_train = input_train / 255
input_test = input_test / 255
target_train = keras.utils.to_categorical(target_train, no_classes)
target_test = keras.utils.to_categorical(target_test, no_classes)
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(32,32,3)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dense(no_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer=keras.optimizers.Adam(),
metrics=['accuracy'])
history=model.fit(input_train, target_train,
batch_size=batch_size,
epochs=no_epochs,
validation_split=0.2
)
The result of the KL Divergence Loss is shown below
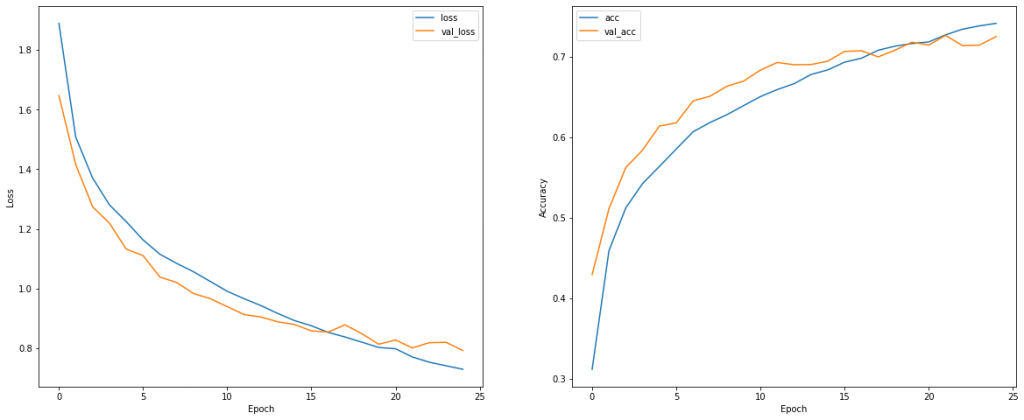
The result of the Cross Entropy Loss is shown below
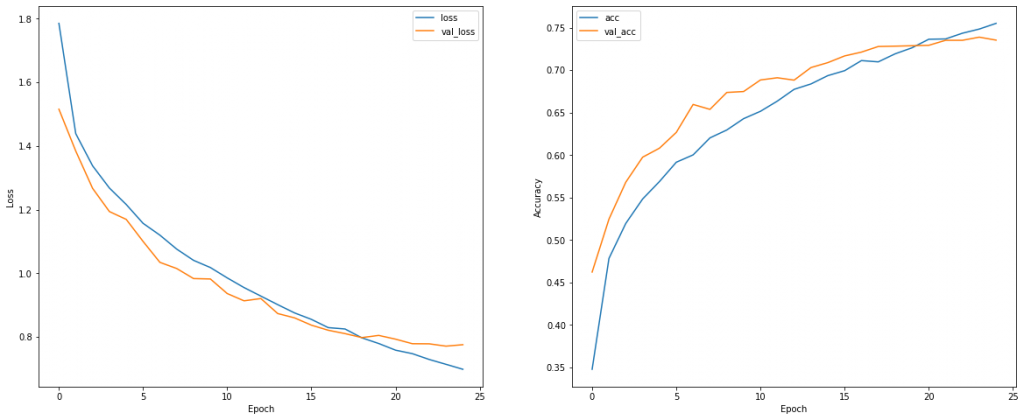
Visually, we do not see a differences in the result for both cases.