Network Compression with Depthwise Separable Convolution
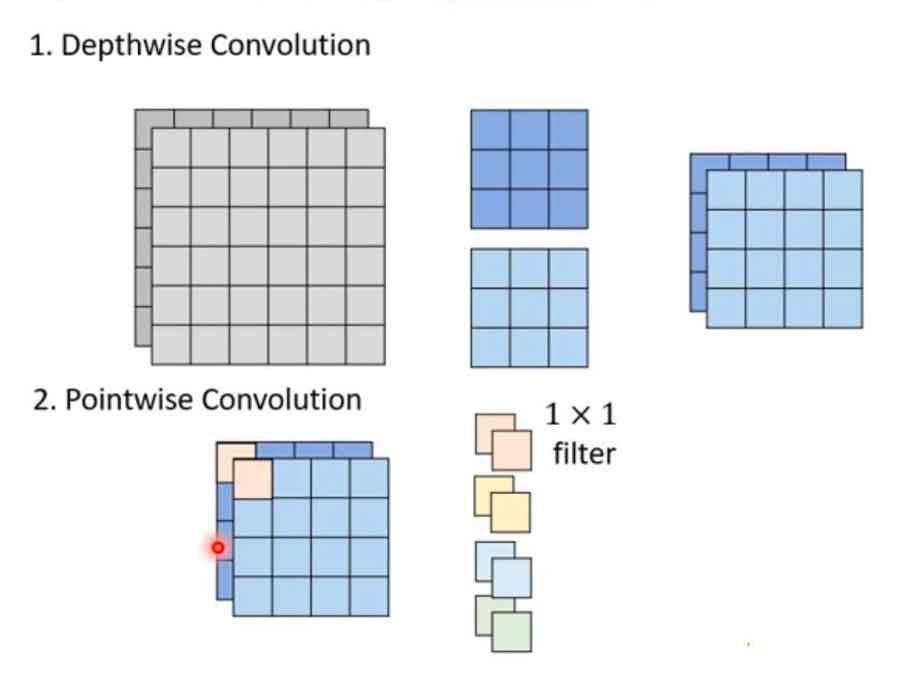
One way to achieve network compression is using depthwise separable convolution. Depthwise separable convolution is used in many pre-trained neural networks such as MobileNet, Xception, SqueezeNet and ShuffleNet.
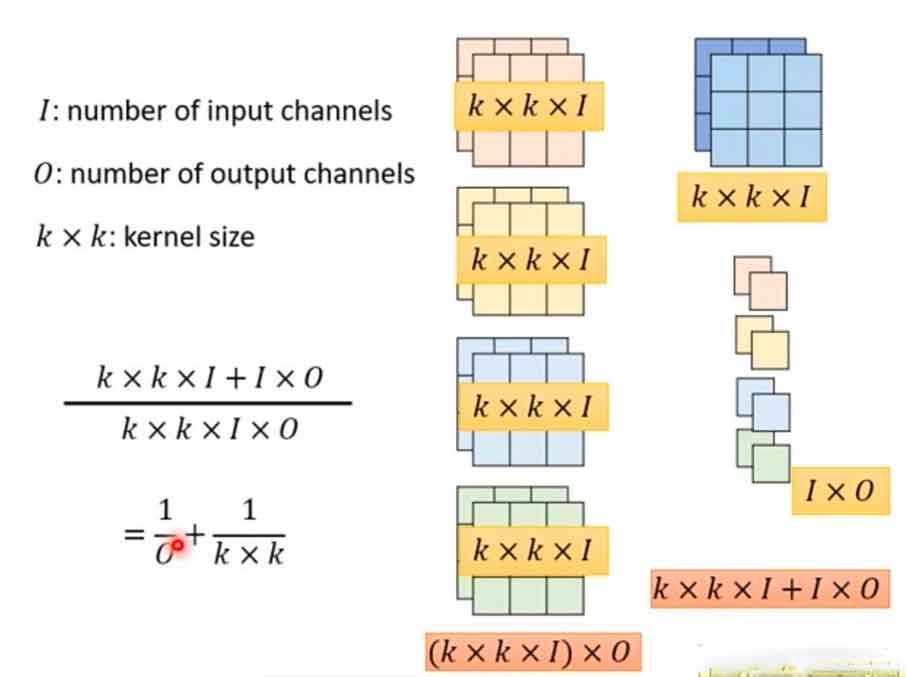
Depthwise separable convolution consists of two steps. Step 1 performs a spatial convolution independently over each channel of an input. Step 2 performs a a pointwise convolution, i.e. 1×1 convolution, over the outputs from Step 1. The number of 1×1 convolution is the number of output channels.
In a conventional convolution, the number of parameters are (k*k*I)*O, while in depthwise separable convolution, the number of parameters are k*k*I + I*O. For large output channels, the reduction of parameters is approximately (1/k*1/k).
Tensorflow and Keras has a DepthwiseConv2D API. We evaluate DepthwiseConv2D API by comparing three models. Model 1, the control model, is the conventional CNN model. Model 2 replaces all the Conv2D with DepthwiseConv2D layers. Model 3 is a hybrid of CNN and DepthwiseConv2D layers. The model code is shown below:
# Model 1: Full Conv2D Model
model = Sequential([
Conv2D(32,3,padding='same',activation='relu',input_shape=input_shape),
MaxPooling2D(),
Conv2D(64,3,padding='same',activation='relu'),
MaxPooling2D(),
Flatten(),
Dense(512,activation='relu'),
Dense(10,activation='softmax')
])# Model 2: Fully DepthwiseConv2D layers
model = Sequential([
Input(shape=input_shape),
DepthwiseConv2D(32,3,padding='same',activation='relu'),
MaxPooling2D(),
DepthwiseConv2D(64,3,padding='same',activation='relu'),
MaxPooling2D(),
Flatten(),
Dense(512,activation='relu'),
Dense(10,activation='softmax')
])# Model 3: Hybrid Conv2D and DepthwiseConv2D layers
model = Sequential([
Input(shape=input_shape),
Conv2D(32,3,padding='same',activation='relu'),
MaxPooling2D(),
DepthwiseConv2D(64,3,padding='same',activation='relu'),
MaxPooling2D(),
Flatten(),
Dense(512,activation='relu'),
Dense(10,activation='softmax')
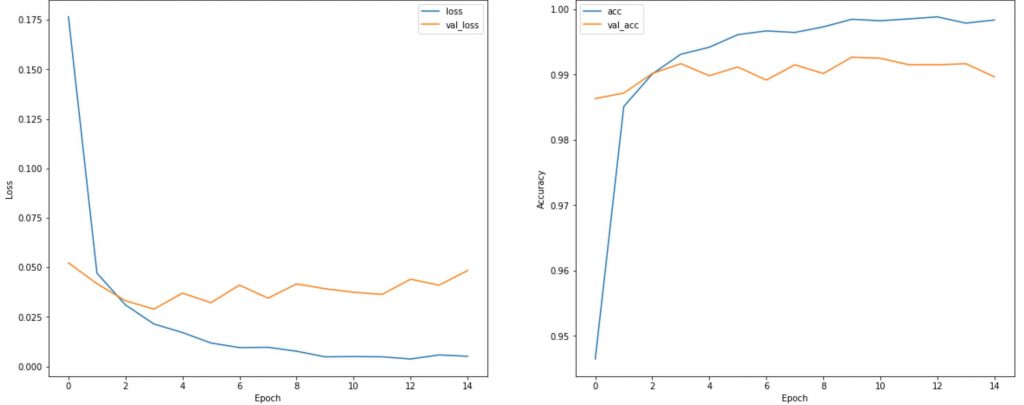
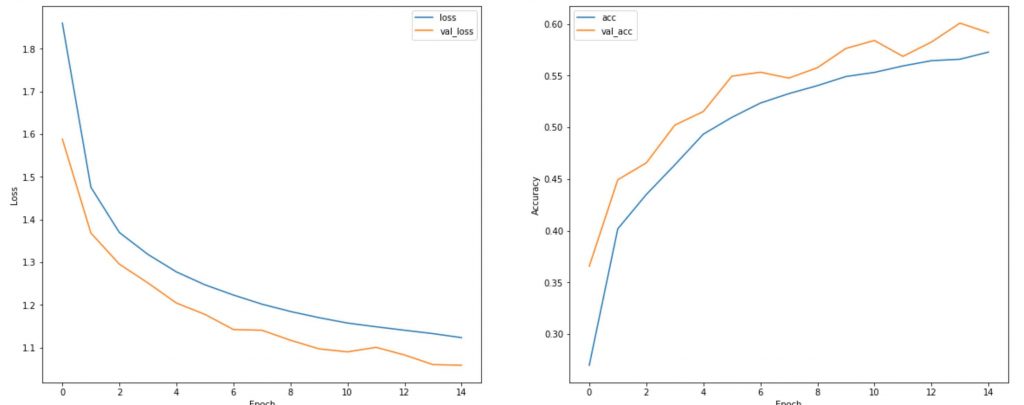
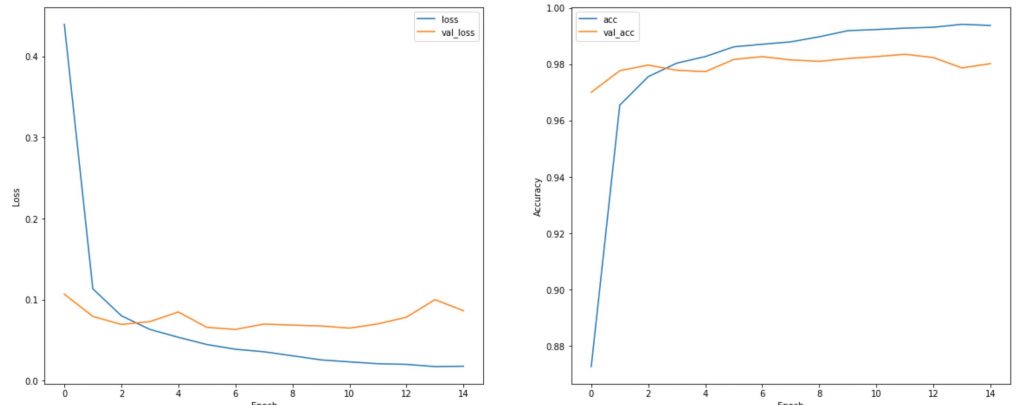
])The loss and accuracy result for the 3 models are shown in the order below. The conventional CNN model achieved a 99% accuracy, while the full Depthwise Separable Convolution model showed a dismay 55% accuracy. However, a hybrid Conv2D and DepthwiseConv2D model achieve a 98%. The experiment shows that Depth Separable Convolution can greatly impact the accuracy, however, a hybrid model achieve a good accuracy with network compression.