Sentimental Analysis Using Tensorflow Keras.
Recurrent Neural Network (RNN) model has been very useful to processing sequential data. Tensorflow Keras is a great platform to implement RNN as the learning curve is less steep as compared to other platforms eg Pytorch framework training. In this article, we will demonstrate how to apply the LSTM model with Tensorflow Keras to for sentimental analysis training. We will use IMDB review dataset as example..
First we load the IMDB dataset as follows:
import keras
from keras.datasets import imdb
from keras.preprocessing import sequence
max_words = 10000
seq_length = 80
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_words)
x_train = sequence.pad_sequences(x_train, maxlen=seq_length)
x_test = sequence.pad_sequences(x_test, maxlen=seq_length)
print('input_train shape:', x_train.shape)
print('input_test shape:', x_test.shape)We define the LSTM moidel as follows:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Embedding
from tensorflow. keras.layers import LSTM
hidden_size = 16
embedding_size = 16
L1 = 32
model = Sequential()
model.add(Embedding(max_words, embedding_size))
model.add(LSTM(hidden_size,activation='tanh'))
model.add(Dense(L1, activation='relu'))
model.add(Dense(1, activation='sigmoid'))To run the model, we use the following condition
model.compile(optimizer='rmsprop',loss='binary_crossentropy',metrics=['accuracy'])
batch = 250
num_epoch = 10
history = model.fit(x_train, y_train, epochs=num_epoch, batch_size=batch,validation_data=(x_test,y_test))We can plot the actual and predicted stock prices using scikit learn and matplotlib libraries
loss = history.history['loss']
val_loss = history.history['val_loss']
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
epoch = range(len(loss))
import matplotlib.pyplot as plt
plt.figure(figsize=(20, 8))
plt.subplot(1, 2, 1)
plt.plot(epoch,loss,label='loss')
plt.plot(epoch,val_loss,label='val_loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(epoch,acc,label='acc')
plt.plot(epoch,val_acc,label='val_acc')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()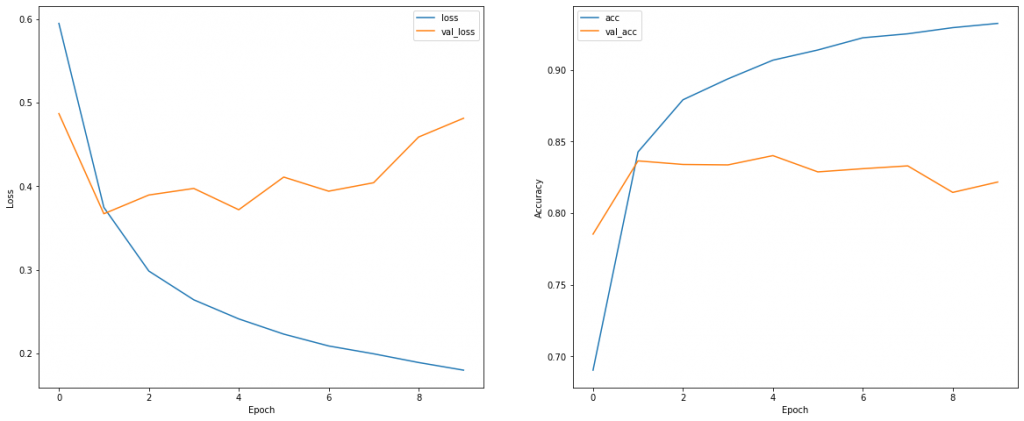
We can test the model as follows:
word_index = keras.datasets.imdb.get_word_index()
text = "This movie is lousy and horrible I feel very sad"
#text =" This movie is very good and nice I feel very happy"
# text = "This movie is lousy and horrible It is wasting my money"
#text ="This movie is good worth the money I love it"
tokens = text.lower().split()
token_index = [word_index[word] for word in tokens]
token_index = np.array(token_index)
token_index = token_index[np.newaxis,:]
pred = model(token_index)
print(f'The sentiment score is {pred} - 0 is negative and 1 is positive')The output of the testing is as follows:
The sentiment score is [[0.10010237]] – 0 is negative and 1 is positive